How to select the right machine learning algorithm

For any given machine learning problem, numerous algorithms can be applied and multiple models can be generated. A spam detection classification problem, for example, can be resolved using a variety of models, including naive bayes, logistic regression and deep learning techniques like BiLSTMs.
Having a wealth of options is good, but deciding on which model to implement in production is crucial. Though we have a number of performance metrics to evaluate a model, it’s not wise to implement every algorithm for every problem. This requires a lot of time and a lot of work. So it’s important to know how to select the right algorithm for a particular task.
In this article, we’ll look at the factors that can help you select an algorithm that best suits your project and your particular business requirements. We’ll do this by looking at a variety of factors that can help you refine your selection. Understanding these factors will help you understand the task your model will perform, and the complexity of your problem.
Factors to consider when implementing an algorithm:
- Interpretability
- The number of data points and features
- Data format
- Linearity of data
- Training time
- Prediction time
- Memory requirements
Let’s take a closer look at each one.
Interpretability
When we talk about the interpretability of an algorithm, we’re talking about its power to explain its predictions. An algorithm that lacks in such an explanation is called a black-box algorithm.
Algorithms like the k-nearest neighbor (KNN) have high interpretability through feature importance. And algorithms like linear models have interpretability through the weights given to the features. Knowing how interpretable an algorithm is becomes important when thinking about what your machine learning model will ultimately do.
For classification problems like detecting cancerous cells or judging credit risk for home loans, the reason behind the system’s results must be understood. It’s not enough to just get a prediction, because we need to be able to evaluate it. And even if the prediction is accurate, it’s imperative that we understand the processes that lead to these predictions.
If understanding the reason behind your results is a requirement for your problem, a suitable algorithm need to be chosen accordingly.
The number of data points and features
When selecting a suitable machine learning algorithm, the number of data points and features plays an essential role. Depending on the use case, machine learning models will work with a variety of different datasets, and these datasets will vary in terms of their data points and features. In some cases, selecting a model comes down to understanding how the model handles different sized datasets.
Algorithms like neural networks work well with massive data and a large numbers of features. But some algorithms, such as Support Vector Machine (SVM), work with a limited number of features. When selecting an algorithm, be sure to take into account the size of the data and the number of features.
Data format
Data often comes from a mix of open-source and custom data resources, and so it can also come in a variety of different formats. The most common data formats are categorical and numerical. Any given dataset might contain only categorical data, only numerical data or a combination of both.
Algorithms can only work with numerical data, so if your data is categorical or otherwise non-numerical in format, then you will need to consider a process to convert it into numerical data.
Linearity of data
Understanding the linearity of data is a necessary step prior to model selection. Identifying the linearity of data helps to determine the shape of the decision boundary or regression line, which in turn directs us to the models we can use.
Some relationships like height-weight can be represented by a linear function which means as one increases, the other usually increases with the same value. Such relationships can be represented using a linear model.
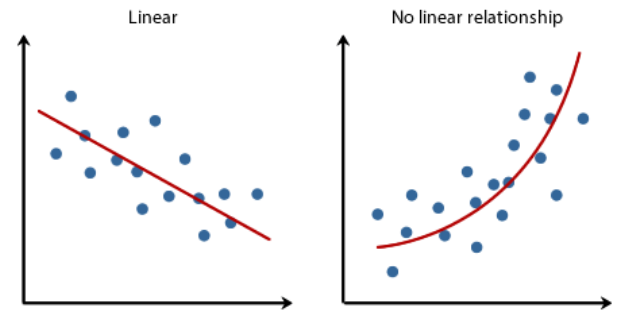
Knowing this will help you select an appropriate machine learning algorithm. If the data is almost linearly separable or if it can be represented using a linear model, algorithms like SVM, linear regression or logistic regression are a good choice. Otherwise, deep neural networks or ensemble models can be used.
Training time
Training time is the time taken by an algorithm to learn and create a model. For use cases like movie recommendations to a particular user, data needs to be trained every time the user logs in. But for use cases like stock prediction, the model needs to be trained every second. So considering the time taken to train the model is essential.
Neural networks are known for the substantial amount of time they require to train a model. Traditional machine algorithms like K-Nearest Neighbors and Logistic Regression take much less time. Some algorithms, like Random Forest, require different training times based on the CPU cores being used.
Prediction time
Prediction time is the time it takes for the model to make its predictions. For internet companies, whose products are often search engines or online retail stores, fast prediction times are the key to a smooth user experience. In these cases, because speed is so important, even an algorithm with good results isn’t useful if it is too slow at making predictions.
However, it’s worth noting that there are business requirements where accuracy is more important than prediction time. This is true in cases such as the cancerous cell example we raised earlier, or when detecting fraudulent transactions.
Algorithms like SVM, linear regression, logistic regression, and a few types of neural networks can make quick predictions. However, algorithms like KNN and ensemble models often require more time to make their predictions.
Memory requirements
If your entire dataset can be loaded into the RAM of your server or computer, you can apply a vast number of algorithms. However, when this is not possible you may need to adopt incremental learning algorithms.
Incremental learning is a method of machine learning where input data is continuously used to extend the existing model’s knowledge, i.e. to train the model further. Incremental learning algorithms aim to adapt to new data without forgetting existing knowledge, so you do not need to retrain the model.
In conclusion
Performance may seem like the most obvious metric when selecting an algorithm for a machine learning task. However, performance alone is not enough to help you select the best algorithm for the job. Your model needs to satisfy additional criteria such as memory requirements, training and prediction time, interpretability, and data format. By incorporating a wider range of factors, you can make a more confident decision.
If you are having a difficult time choosing the best algorithm for your data among a couple of selected models, one popular model selection method is to test them on your validation dataset. This will give you metrics by which you can compare each model and make a final decision.
When deciding to implement a machine learning model, selecting the right one means analyzing your needs and expected results. Though it may take a little extra time and effort, the pay off is higher accuracy and improved performance.



