The essential guide to entity extraction

Entity extraction, also known as entity identification, entity chunking and named entity recognition (NER), is the act of locating and classifying mentions of important information that is generally categorized as a noun in a piece of text. This is done using a system of predefined categories, which may include anything from people or organizations to temporal and monetary values.
The entity extraction process adds structure and semantic information to previously unstructured text. It allows machine-learning (ML) algorithms to identify mentions of certain entities within a text and even summarize large pieces of content. It can also be an important preprocessing step for other natural language processing (NLP) tasks.
With a wide range of potential use cases, from streamlining customer support to optimizing search engines, entity extraction plays a vital role in many of the NLP models we use every day. This includes the large language models that power generative AI. An understanding of this field of research can play a role in helping your business to innovate — and stay ahead of the competition. However, as with many fields of machine learning, it can be hard to know where to begin.
With these challenges in mind, we’ve created this guide as a crash course for anyone keen to start exploring the world of entity extraction. Covering everything from the basic makeup of an entity to popular formatting methods, the content below will help you get your own entity extraction project up and running in no time.
Let’s get into entity extraction.
What is an entity?
Generally speaking, an entity is anything that has a distinct and self-contained existence. This can be physical, such as a dog, tree or building. It can also be conceptual, such as a nation, organization or feeling. As mentioned, linguistically the vast majority of nouns can be considered entities in some shape or form.
However, such a broad definition of entities isn’t particularly helpful when it comes to entity extraction. Instead, researchers tend to extract only named entities from a text. Named entities usually have a proper name, and differ from entities as a whole in that they indicate the exact same concept in all possible instances. 'Apple', 'Freddie Mercury' and 'the Bank of Japan' are all named entities, while 'apple', 'the musician' and 'the bank' are not. This is because 'Freddie Mercury' is inextricably connected to the lead singer of the band Queen in all its uses, whereas 'the musician' could refer to Mick Jagger, Beyoncé or anyone who enjoys playing the guitar. While the meaning of an entity can change depending on context, a named entity is always linked to one specific concept.
In the strictest possible sense, named entities can also be referred to as rigid designators, while entities with a more fluid meaning can be described as flaccid designators. However, there is actually a slight difference between rigid designators and named entities. Rigid designators only encompass terms with an unbreakable link to a certain concept. In contrast, there is a general consensus among NLP researchers that, for practical reasons, certain other things like currency and time periods can be considered named entities.
What is entity extraction?
In this context, extraction involves detecting, preparing and classifying mentions of named entities within a given piece of raw text data. This can be done manually, using annotation tools like browser-based rapid annotation tool (BRAT), or through the use of an NER solution. The categorization system that these entities are sorted into can be unique to each project. Entities can be categorized into groups as broad as 'people', 'organizations' and 'places', or as narrow as 'soluble' and 'insoluble chemicals'.
Before it’s possible to extract entities from a text, there are several preprocessing tasks that need to be completed. For example, tokenization helps to define the borders of units within the text, such as the beginning and end of words. Part-of-speech (POS) tagging annotates units of text with their grammatical function, which helps to lay the foundations for an understanding of the relationships between words, phrases and sentences. These processes help the machine to define the position of entities and begin to extrapolate their likely role within the text as a whole. Despite their necessary role in entity extraction, they’re not usually defined as such. Instead, data scientists will usually assume that these preprocessing steps have already been completed when discussing their extraction project.
However, this doesn’t change the fact that entity extraction is a complex, multi-step process. Under the umbrella of entity extraction, there are several other, slightly different tasks that add to the breadth and depth of what it’s possible to do with named entities. To give just one example, coreference resolution can be vital to the success of any entity extraction project. This process ensures that various different ways to describe a certain named entity are all recognized and labeled. For example, 'Marshall Mathers', 'Mathers' and 'Eminem' all refer to the same person and need to be identified in this way in the text, despite the difference in words used to describe them. Coreference resolution can be performed either in-document or across several documents, which enables an algorithm to link two documents that mention a certain entity together.
Before and after entity extraction
Before any entities can be extracted, there has to be some raw text input. There are a range of different ways that we could progress here, depending on the classification system we use. We could choose to extract only one general type of entity, such as people, or a range of more specific entity types, such as actors and actresses or fictional characters.
Once we’ve decided on our classification system, labels can be added to a text using open-source tools like BRAT. After we’ve finished annotating, our text output might look something like this:

One important thing to note is that while the meaning of named entities does not change, the way that you choose to classify them is highly subjective. While the phrase 'Abraham Lincoln' always signifies the same person, he could be labeled as a 'person', 'president' or 'American', among other things. The categories in our example are just one possible way to group these named entities. Depending on the other pieces of text in the dataset, certain labels may make more sense than others.
Key terms
The field of entity extraction has a selection of technical terms that it’s important to know. While we’ll discuss some of these in more detail later on, here’s a list that will quickly reinforce your knowledge:
Coreference resolution: In natural language processing, this task primarily involves finding and tagging different phrases that refer to the same specific entity. For entity extraction purposes, this might involve identifying which categories the words 'she', 'he' or 'it' belong to.
F1 score: Also called F-score, this is a method used to judge a program’s accuracy. It takes into consideration an algorithm’s precision and recall. The best F-score is 1, while the worst is 0. The formula to calculate F-score is as follows:
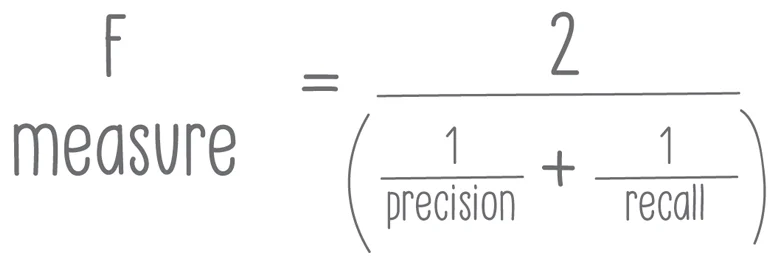
Information extraction: This is the process of retrieving structured information from unstructured documents. It usually involves drawing information out of human-language text through the use of natural language processing.
Inside-outside-beginning (IOB): IOB is a common way to format tags in chunking tasks like named entity recognition. In this system, each word is tagged to indicate whether it is the beginning of a chunk, inside a chunk, or outside of a chunk. IOB2 is also a commonly used format, which differs slightly in its use of the “B” tag.
Keyphrase tagging: This task involves finding and labeling the words or phrases in a text that are most relevant to its subject. It’s particularly important for those building text mining or information retrieval algorithms.
Named entity recognition (NER): Often used as a synonym for entity extraction, NER involves tagging words or phrases with their semantic meaning, such as 'person' or 'product'. These semantic categories are usually laid out in project guidelines.
Precision: This quality metric assesses how many relevant examples are found in an algorithm’s results. For example, if an algorithm returns 10 examples of 'person' entities but only seven are correct, the algorithm’s precision would be 7/10. High precision means that a program returns more relevant results than irrelevant ones.
Recall: Recall measures the number of correct results a program identifies from the total number of correct results. For example, if there are 20 'company' entities in a text and the algorithm finds 10, its recall is 10/20 or ½. High recall means that an algorithm is able to return most of the correct results.
Semantic annotation: This is the process of labeling texts with additional information so that machines can understand them. It’s also known as semantic tagging or semantic enrichment. Entity extraction is just one of the methods used to add this information to text segments.
Standoff format: This is a popular method of formatting entity extraction data that only displays the entities that are found in the text, as opposed to the entire text. It uses a combination of codes to indicate where the entity can be found in the original text.
Why is entity extraction important?
Entity extraction is one of the building blocks of natural language understanding. By adding structure to text, it paves the way for a whole host of more complex NLP tasks — as well as being an end goal in itself.
Through entity extraction, it’s possible to start summarizing texts, locate mentions of particular entities across multiple documents and identify the most important entities in a text.
Applications of entity extraction
The tasks mentioned above have a wide variety of business use cases. Let’s take a look at some of them within different business areas.
Brand perception assessment
Having your finger on the pulse of what your customers are saying about your brand via public outlets (survey responses, product reviews, social media posts and more) is essential for knowing what your business is doing well, and not so well. For example, social listening tools use entity extraction to automatically detect and track mentions of a brand, product or service across platforms. When combined with a tool that performs sentiment analysis, you can gain even further insights into how customers perceive your brand.
Product recommendations
Entity extraction is also key to delivering product recommendations tailored to specific customer preferences and past purchasing behavior. It does this by identifying specific entities within your product description and then automatically detecting other products that contain similar entities.
Customer service ticket routing
Sorting customer service requests to route them to the appropriate agent can be a monumental task. Entity extraction automates this process by identifying relevant information (product names, emails, shipping dates and more) within the tickets and routing them to the person responsible.
Resume filtering
Entity extraction helps to filter through resumes to identify the most appropriate candidates based on particular tagged criteria such as education level, experience and more.
Search engine optimization
Extracting key phrases and terms from a webpage helps search engines to understand the content that’s found on that page. This helps search engines to deliver more relevant results to a particular query.
Managing your entity extraction project
Whether you’re looking to build your own entity extractor or outsource the project to a trusted partner, there are a number of challenges to navigate as you build the best possible machine learning model. One of the biggest is obtaining clean, focused training data. Regardless of your level of involvement in building your entity extractor, a quality dataset will provide it with some near-perfect examples of how to do the task you’re looking to accomplish. It’s crucial to get them right.
For every stage of an annotation project, there are some best practices to consider. These can help you achieve your desired ROI by ensuring the resulting dataset helps you to build a great entity extractor.
Establishing guidelines
For every project, it’s crucial to have clear guidelines. At the start of a project, it’s essential to develop a comprehensive document that clarifies exactly what you expect from the tagging process and gives clear instructions to your annotators. The development of these guidelines centers on two things: the classification system and best practices for annotation.
When you establish your classification system, the main focus should be on understanding exactly what all of the labels in the system mean on both a macro and micro level. It’s crucial to understand what each category and sub-category contains. For example, in many cases hotels are tagged as companies, but in certain industries, such as travel, they’re often tagged as locations. You should also outline any specific tagging requests in detail. When tagging dates, it’s important to know if the category should be restricted to phrases like “August 17th,” or whether “tomorrow” or “the 17th” should be included. While the goal is to cover as many of these scenarios as possible beforehand, it’s inevitable that your guidelines will continue to grow throughout the project as your annotators encounter fresh edge cases.
The second half of the guidelines deals with all of the ways in which you expect tagging to be completed. This goes far beyond knowing how many tiers the classification system will stretch to. To work effectively, your annotators will need to know how to deal with a range of potential issues, such as punctuation, nicknames, symbols, spelling errors and junk data that falls outside of all categories. It’s also important to give them an idea of the density of annotated entities within each raw text sample.
Annotation and quality controls
Annotation initially sounds rather straightforward. At a high level, an annotator should read each raw text sample, highlight certain words or phrases and add an appropriate label using a text annotation tool. However, you have to work extremely carefully to avoid common errors that could compromise your dataset.
It’s commonly forgotten that entity annotation isn’t just a language exercise, but also a cultural exercise. This can manifest itself in unusual ways. To give just one narrow example, many projects require that names are only tagged when they refer to a person entity. In this case, 'Walt Disney' and 'Snow White' should be tagged, but 'Mickey Mouse' should not, since he isn’t human.
Further to this, words have an awkward habit of changing categories, often within the same paragraph. This can be seen in the names of institutions, such as 'Bank of Japan'. On its own, Japan should be tagged as a location, but as part of this phrase it should be tagged as an organization. This issue is even more apparent in the Japanese translation, where the word for Japan — 日本 — is actually contained within the compound name of the company — 日本銀行. As a result, annotators have to be alert to changes in language use, subject and nuance within a piece of text to ensure that every data point is attached to an appropriate label.
If you have a team of multiple annotators working on your dataset, it can be even more taxing to annotate effectively. If this is the case, it’s important to put processes in place that enable constant communication and the rapid resolution of any questions from your team of annotators. For example, online forms that allow annotators to quickly and easily submit questions can be a massive help. If it’s within your scope, a project manager can also be invaluable in monitoring submissions, identifying irregularities and providing feedback.
Fortunately, entity extraction is pretty objective when it comes to quality. Inter-reliability checks can be useful in determining whether your team of annotators has correctly understood the task. However, since entity extraction is not as subjective as other data annotation tasks, there shouldn’t be as much need to compensate for a variety of approaches to the initial raw data.
Packaging and exporting
Once all the relevant entities have been identified and labeled, it’s time to format the data. There are several possibilities here, but there are two particular methods of presenting the data that are worth mentioning.
The IOB2 format, where IOB stands for inside-outside-beginning, is a method of tagging in which the annotations are attached directly to each word. The key advantage of this method is that it includes the entire text, regardless of whether the word is part of an entity.
Sometimes, entity extraction results are provided in JSON format so that the information is more easily processed by other systems. In JSON, this information is provided in a similar way to IOB2.
Standoff format is most prominently used on the popular text annotation tool BRAT. It differs from the IOB2 format in that it shows only the entities that have been tagged. The text and annotations are often split into two separate documents. This makes the files look rather different:

Here, 'T' indicates the entity number, while the three-letter code explains which type of entity it is: in our case, names, locations and companies. The two numbers indicate the character numbers the entity can be found between. Finally, on the far right is the entity as it appears in the data. One benefit of this format is that it gives you a simple list of entities to work with, making your data more streamlined and easy to manage.
Once the data has been correctly formatted, it’s ready to be used for training your ML model.
Conclusion
Entity extraction may not be as glamorous as other machine learning tasks, but it’s absolutely critical to the ability of machines to understand language. As the volume of new data available to us increases exponentially, the process that adds structure to this chaos will be more valuable than ever.
Whether it’s used as a preprocessing step or it’s the end goal in its own right, entity extraction is poised to play a huge role in the business world of the future. By improving machine understanding of language, it will ultimately make us more informed, effective and capable of providing the stellar service our customers deserve.



